Appearance
Indexes
The Search Index is essential to your search functionality. It is here that you define what fields should be searchable for a given entity type (products, product variants, product categories, content, content categories), as well as defining the weight of these searchable fields. Without a Search Index, your search functionality will not function as intended, as the Relewise Search Index by default only looks at ID and DisplayName, and nothing else. As such, Relewise highly recommends taking the time to go through the Search Index and configuring it according to your needs.
Different entities come with certain fields as standard (most commonly DisplayName and ID), but you should add whatever Data Keys are relevant for your entities into the index, so that you can assign weight to them. To enter a Data Key into the index, simply enter the name into the available field, and assign it a weight and prediction source type (explained below).
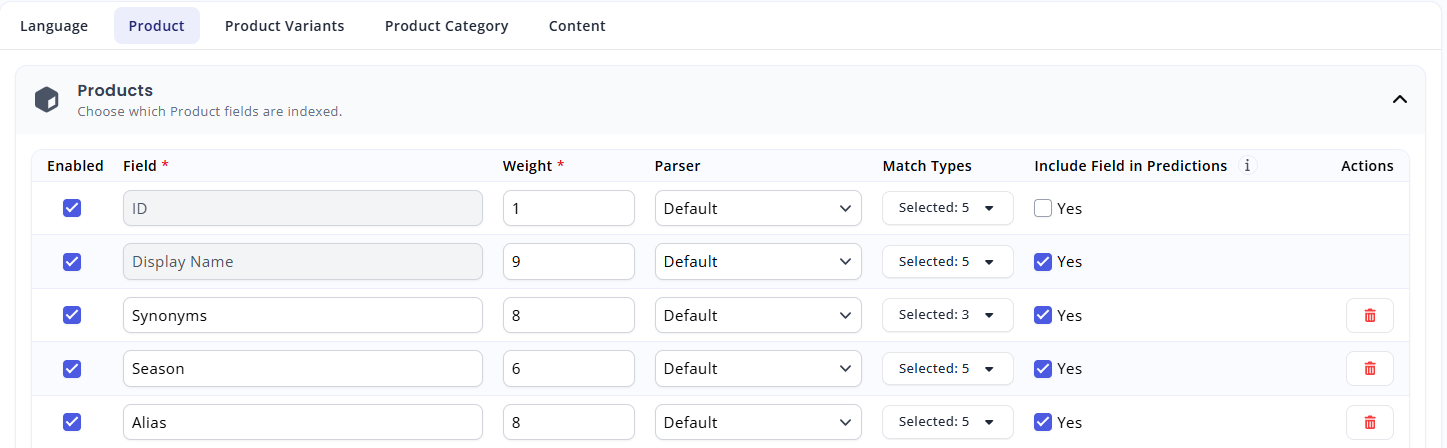
Example of an index with a custom field and specified weight
On Having More Than One Search Index
By default, Relewise provides you with one Search Index for you to configure. In the vast majority of cases, this is sufficient to give you the control you need, even with multiple languages to configure. If, however, you find that you require more than one Search Index, we urge you to reach out to us and discuss the possibilities of having another index added to your Dataset.
Data Key Autosuggest
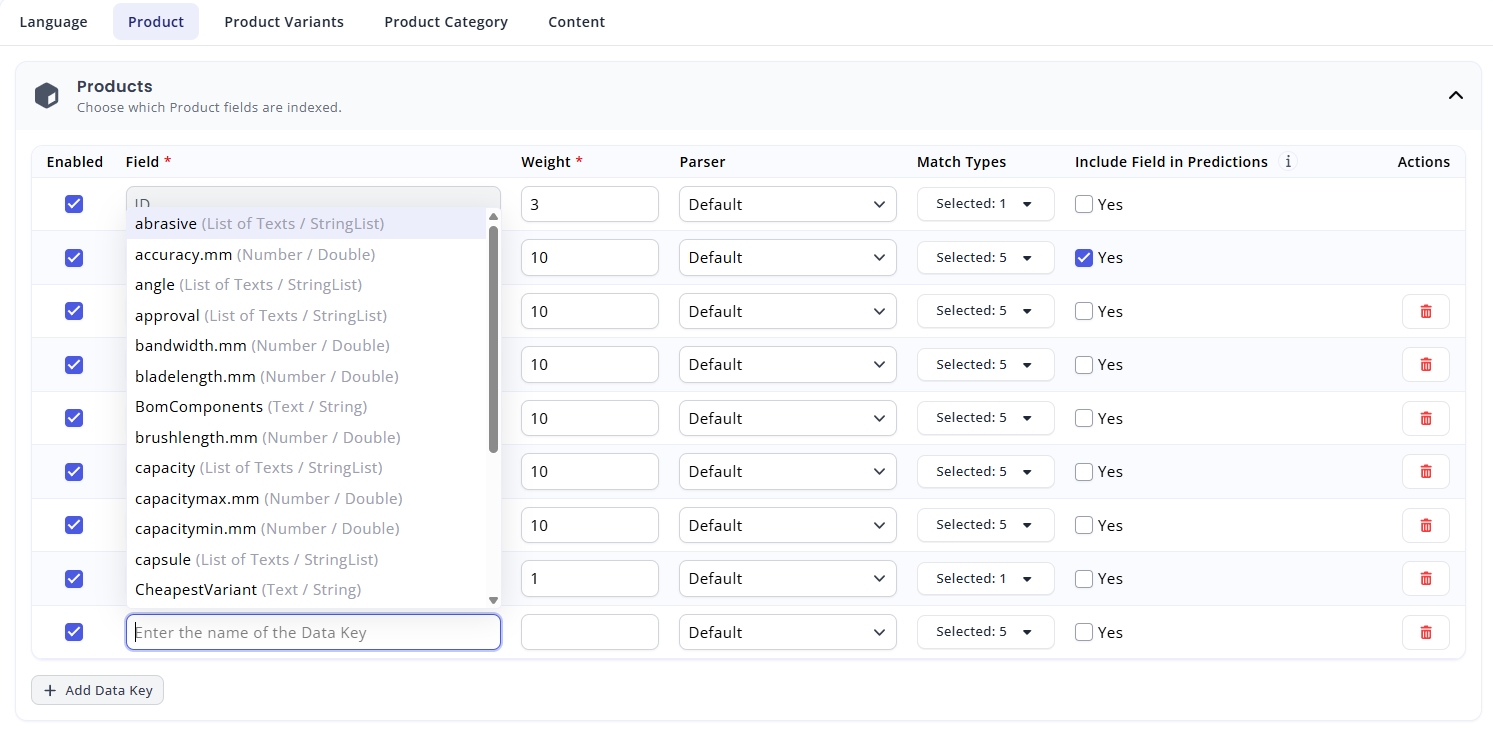
The Search Index is outfitted with a function that tries to help you target the correct data keys. When you click to add a new data key to the index, the system will try to match your input to data keys that exist on the relevant entity type. Be aware, however, that this system may not suggest all available data keys, and only fetches the first 500 entities of the given type to probe for key names. If the key does not exist on any 500 fetched entities, it will not be suggested by the index. This does not mean that you cannot index the field, however; you will simply have to type it in manually, or copy it from the entity data itself.
Stale Data
When adding new entities or updating/importing new texts (via, for instance, a Product or Content Update) there is a delay while the new index is being rebuilt before search results will reflect the change.
How long it takes depends on the size of the index, the number of entities on the dataset, the number of fields being indexed, etc. It may be anywhere between 1 minute and in worst case a few hours. Most often it takes between 2-15 minutes.
The best way to know how long it usually takes for your data to be reindexed is to visit the Search Index page and find the “Last stale duration” period. Unless you have added a significant amount of new data, or are indexing a significant number of new data keys, the time spent will typically be the same.

You can learn more about the rebuild time on the Search Index page
Search Index Weight
Field Weighting in Search
Weight is a score assigned to a data field to determine its influence on search relevance. It is a numeric value (byte) ranging from 1 to 255, where higher numbers indicate greater importance. These weights are relative—both to each other and to the maximum assigned value.
🔢 Example
- Two fields with weights
1and2:
→ The second field is 100% more influential than the first. - Three fields with weights
1,2, and3:
→ Field2is 33% stronger than field1, and
→ Field3is 66% stronger than field1.
📊 Impact on Search Ranking
- Large differences in weights lead to a strong impact on result ordering.
- Smaller differences allow other ranking factors to take over, such as:
- Personalization
- Popularity
- Relevance modifiers
- Merchandising rules
💡 Tip: Use higher weight differences when you want to ensure a specific field dominates search relevance. Use similar weights when you'd like other dynamic signals to play a bigger role.
Weight affects a search term only once. A search term will not gain additional weight from being present in multiple fields, and only gains the weight of the most prominent field it is associated with. In a search with multiple terms, each unique term can gain its own weight, which can help increase search accuracy.
When weighting fields, it can be useful to set some fields at the same weight value. Weighting works in tandem with the Relewise personalization engine, and this method allows the personalization to push the more relevant results to the top of the search. This is also a useful tool if you want to test which of two fields might be more useful to your users; set them as the same weighting, and compare the results of searches after a few weeks.
To avoid cluttering search results, it is recommended to set the weight of any field containing a lot of text (such as product descriptions or the body of a content page) to 1.
Brand Weighting
If products have Brands associated with them, it is possible to configure the Search Index to match products to searches for Brand ID and/or Brand Display Name. This allows you to, for instance, easily find all products associated with the brand Nike, simply by configuring the Brand Display Name.
Unlike Category Weighting, Brand Weighting can only be configured for Brand ID and Brand Display Name. If you need further custom, brand-related data for your product search, we advise adding the data to the product entities themselves.

Category Weighting
Similar to Brand Weighting, it is possible to configure the Search Index to match product results to data contained on their related Product Categories. This means that if you have a product category named Linen Trousers, and have configured the Category weighting to include Category Display Name in the index, users will be able to find all products related to the Linen Trousers product category by searching for "linen trousers".
Category Weighting can be configured to target custom Data Keys located on the Product Category entities, by using the Add Data Key button.
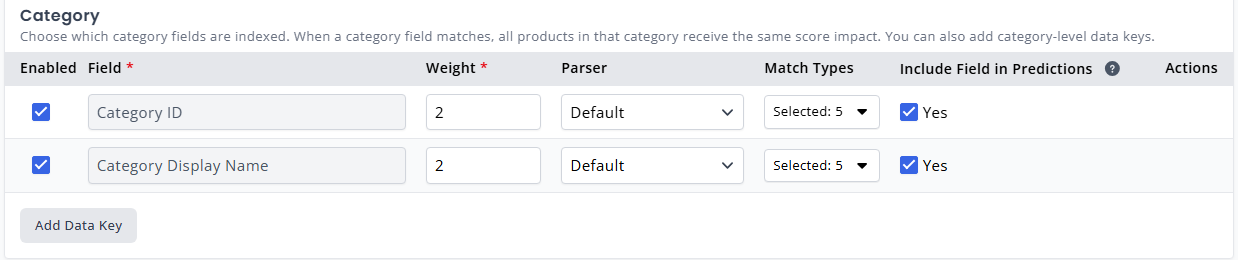
Category versus Product Category
Category Weighting, in this context, is focused on finding product entities. It basically identifies products on the basis of the data that exists on the categories associated with them.
The Search Index also allows you to configure Product Category search. This refers specifically to searching for Product Category entities, which is useful if you want to allow users to search for categories directly.
In short: Category Weighting under the Products tab refers to finding products in the search. Weighting under the Product Category tab refers to finding product categories in the search.
Include Field in Predictions
This feature toggles whether the particular data field should be used for the purpose of Search Term Prediction. Toggling it on means that the data contained within the specific field will be used to attempt to predict what a user is typing. As such, it is best used with data fields that contain brief texts, such as Display Names.
Search Match Types
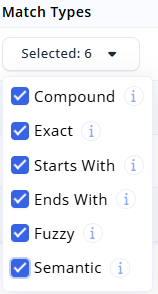
The index can be configured with six different match type settings. Match Types define how a particular field is treated by the search engine, and helps shape the behavior of your Relewise search.
In brief, the match types function as follows:
- Compound – the query merges multiple words into a single term, e.g., “key board” matches “keyboard.”
- Exact – the query and indexed word are identical, e.g., “cat” matches “cat.”
- StartsWith – the query matches the beginning of an indexed word, e.g., “cat” matches “caterpillar.”
- EndsWith – the query matches the ending of an indexed word, e.g., “ball” matches “football.”
- Fuzzy – the query matches via spelling correction or similar editing distance, e.g., “keybord” matches “keyboard.”
- Semantic – the query matches by meaning rather than exact wording, e.g., “sofa” can match “couch,” and “vehicle” can match “car,” “truck,” or “bus.”
Match Types: Compound
The Compound match type allows the search to merge multiple words into a single term, to match on indexed compound words. In essence, the compound matching will attempt to join the searched-for terms together to see if the union of these words will match with anything indexed on the dataset. In this way, compound matching is the opposite of decompounding; where decompounding is done during indexing to try and identify constituent parts of compound words and "split them up" to allow for better matches, compound matching instead tries to join the searched-for terms together, to see if that yields results.
Use case example
User searches for dog house. The compound setting attempts to merge the two words together, thus creating doghouse, which matches an indexed term.
Match Types: Exact Match
The Exact Match match type allows the search to match on indexed data where the queried term matches exactly with the Data Key value of the entity. Exact matching does not allow for spelling mistakes; that is handled by the Fuzzy match type. Exact Matching is useful for most searchable data types, but often requires assistance from the other match types to make up for partial matches, spelling errors etc.
Exact matching is used for just about every type of data available. For fields where precision is important, such as for Product IDs, SKUs, or similar, using only exact matching is generally preferred.
Use case example
The user searches for dog house, which matches on the DisplayName for the entity Dog House.
Match Types: Starts With
The Starts With match type allows the search to match on indexed data where the queried term matches the start of a searchable field. This is generally useful for assisting users in matching on partial searches, such as the beginning of a Product ID or Display Name.
Use case example
The user searches for dog, which matches on the start of the DisplayName for the entity doghouse.
Match Types: Ends With
The Ends With match type allows the search to match on indexed data, where the queried term ends with the Data Key value of the entity. This is generally useful for assisting users in matching on partial searches, such as within entity descriptions.
Ends With matching is rarely employed without also employing Starts With matching.
Use case example
The user searches for house, which matches on the end of the DisplayName for the entity doghouse.
Match Types: Fuzzy
The Fuzzy match type allows the search to match on indexed data where the queried term is a close-but-not-exact match to existing data, e.g., words that are spelled incorrectly or contain typos. The fuzzy algorithm will attempt to match within 1-2 characters of the searched-for term (the exact edit distance differs and is based on a percentage calculation of the length of the search term itself), favoring a lower edit distance wherever possible. For searches where two or more possible matches for a fuzzy result might be possible, e.g., "mouse" and "house" both being one distance away from the (likely typoed) search term "jouse," both matches will be considered as equal, and the resulting entities will be ranked according to the relevant sorting logic employed by the search request.
Fuzzy matching is generally helpful to guide users to a good match, but is discouraged for fields where two terms that differ by only a single character, such as Product IDs, SKUs, dimensions, or similar number-based fields.
Use case example
The user searches for doghose, which is within 1 character distance to the DisplayName for the entity doghouse.
Match Types: Semantic
The Semantic match type allows the search to match indexed text by meaning, even when the query does not use the same words as the indexed field. This is useful when users search with synonyms, related concepts, or more natural language phrasing. For example, a search for sofa may match a Product with the DisplayName couch, and a search for running shoes may match a Product described as trail sneakers.
Semantic matching should be enabled deliberately. For best results, and to keep result noise low, enable Semantic only on fields where meaning-based matching is desired. In many setups, this will be a focused field such as DisplayName. Enabling semantic matching on too many fields, or on very broad fields such as descriptions, can make the search return too many unwanted results because loosely related text may be considered relevant.
Use case example
The user searches for couch, which semantically matches the DisplayName for the entity sofa.
Category Scope
Category Scope controls how Product, Product Category, and Content results are found by matching fields on their related categories. It defines where in category tree the search should look when evaluating category field matches, and will override the default category indexing setup so for example, closer categories can be weighted higher than categories further up the tree.
The available scopes are:
- Immediate Parent: only the entity’s direct category is used for matching.
- Immediate Parent Or Its Parent: the direct category and its parent are both considered.
- Ancestor: any ancestor in the category hierarchy can be matched.